Sidebar
<latex>{\fontsize{16pt}\selectfont \textbf{GPU Based Rigid Body Dynamics for Planning and Control}} </latex>
<latex>{\fontsize{12pt}\selectfont \textbf{Markus Wulfmeier}} </latex>
<latex>{\fontsize{10pt}\selectfont \textit{Master Project ME}} </latex>

<latex> {\fontsize{12pt}\selectfont \textbf{Abstract} </latex>
GPUs have lately come into the focus of various research areas. A high number of specialized cores and the resulting benefits in parallel computation lead to significant advantages over the Central Processing Unit (CPU). In this work, the numerical capabilities of GPUs are applied to the calculation of rigid body dynamics, in particular to solving the forward dynamics problem.
Compared to previous research, this approach focusses particularly on the parallelization of rigid body dynamics for small systems in the order of tens of bodies. To take full advantage of the GPU's capabilities in this context, the calculations are parallelized on additional levels other than the number of independent bodies.
<latex> {\fontsize{12pt}\selectfont \textbf{Theoretical Background} </latex>
Graphics Processing Unit
On the GPU, the smallest computation unit is a thread. The thread basically represents all instructions to be performed on the data and different threads process different data sources. Threads are organized on two levels: blocks of threads, which are themselves organized in a grid of blocks. By defining the dimensions of block and grid, the software engineer defines the way the problem is addressed.
Each threads is correlated to one core on the hardware side. The cores are organized into multiprocessors of multiple dozens or hundreds of cores. Modern GPUs can contain thousands of cores in total. There exist various types of memory on the GPU, which can be generally divided into fast memory with very limited availability and slow memory, which is available in the order of gigabytes.
Rigid Body Dynamics
To achieve efficient computation of forward dynamics, this work is based on Featherstone's Articulated Body Algorithm (ABA).
This algorithm propagates the system constraints along the kinematic tree in order to be able to solve the accelerations of all joints, one by one. It can be divided into three serial passes, where the final one determines link and joint accelerations.
<latex> {\fontsize{12pt}\selectfont \textbf{Implementation} </latex>
Starting point builds a CPU-based software for the Articulated Body Algorithm for the hydraulically actuated quadruped HyQ. After the serial CPU-based implementation is adapted to the GPU's structure, there are two basic layers for dividing the work for each motion rollout. Based on HyQ's kinematic structure, the complete calculations can be divided to be performed in different threads. The branch-based implementation uses one core for each leg of HyQ and the link-based approach goes one step further and uses one core per link. While the branches are basically independent of each other and this approach just needs synchronization regarding the floating base, the link-based approach leads to additional synchronization breaks, when a link's state also depends on propagated values from previous links.
 | 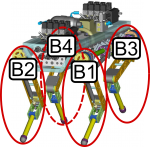 | 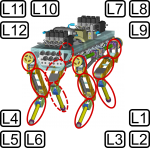 |
| HyQ Kinematic Structure | Branch-Based Approach | Link-Based Approach |
|---|
Furthermore, the calculation of each single equation can be parallelized in a way that one core is responsible for the calculation of one row of the results. Additional methods were implemented to enable the division of single equations onto multiple cores.
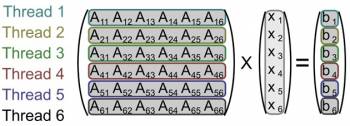
<latex> {\fontsize{12pt}\selectfont \textbf{Analysis} </latex>
The final versions include: the serial algorithm, a branch-based and link-based approach and the matrix-based implementation, which divides each single equation onto multiple cores. These versions are compared against each other and versus the CPU-based forward dynamics. This evaluation of the different parallel versions is based upon the computation time for complete motion rollouts. These rollouts area calculated through a loop of computing the accelerations for the current state and successively integrating to determine the new state.
Computation on the CPU linearly increases with the amount of rollouts to calculate, since the computation happens successively. Because of memory limitations regarding the fast memory, parallel rollouts on the GPU are limited to 84 at a time. Hence, the calculations on the GPU are performed in steps and whenever multiples of 84 are exceeded the absolute computation time increases and the best performance is reached directly before these steps.From all compared approaches, the link base approach offers the best results and provides an acceleration toward the CPU of 8 to 9 times.
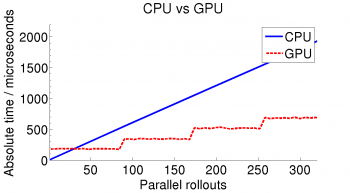 | 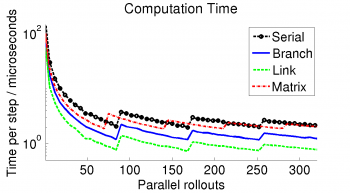 | 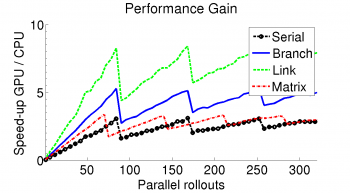 |
| Absolute Calculation Time | Time per Step | Performance Gain |
|---|
<latex> {\fontsize{12pt}\selectfont \textbf{Conclusions} </latex>
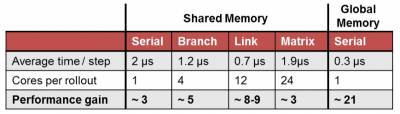
As shown in the table below, the link-based approach does not use the most cores or provides the highest occupancy, but still delivers the best result with the fast type of memory. In this way, it is shown that lower occupancy is in some cases able to improve the performance regarding other metrics as computation time.
It is illustrated that for smaller number of rollouts, the link-based fast memory implementation can provide an acceleration of about 8 times. A different implementation was developed for higher numbers of rollouts, which is basically a serial approach to the problem based on slow memory. This approach bypasses the limitations of shared memory and benefits by being only constrained in parallelism by the number of cores. Because of slower memory access, this approach is unsuited for small batches of rollouts and finds its application for application with a need of rollout batches in the order of multiple thousands.
<latex> {\fontsize{12pt}\selectfont \textbf{Future Work} </latex>
- Forward dynamics algorithms:
This work is based on the ABA, which is currently the most efficient serial algorithm for the calculation of forward dynamics. There exists a variety of different algorithms, which might provide advantages. The Divide and Conquer Articulated Body Algorithm (DCA-ABA) represents Featherstone's expansion of the original ABA for multiprocessor CPUs. Another promising approach is the Assembly-Disassembly-Algorithm by Yamane and Nakamura, which also parallelizes each single rollout.
- Code Generation:
The software developed in this work is based on forward dynamics code for the CPU, which is generated by Marco Frigerio's robotics code generator http://www.iit.it/index.php?option=com_content&catid=10&id=1253&lang=en&view=article. A further aim would be to enable a more generally applicable GPU-based version of forward dynamics software for different kinetic structures and different robots by adapting the templates for the generator and providing a general version, which is able to generate GPU-based forward dynamics code.
- Kinodynamic Planning:
To evaluate the performance benefits in real life scenarious, the developed code can be integrated into kinodynamic planning. Previous research by Park et al. already ported collision checking for path planning to the GPU and a combination of both approaches could lead to a significant acceleration for kinodynamic planning.
Page Tools
