Sidebar
<latex>{\fontsize{16pt}\selectfont\textbf{Learning Motion Control of Robotic Arms}</latex>
<latex>{\fontsize{16pt}\selectfont\textbf{ via PILCO: Python Implementation}} </latex>
<latex>{\fontsize{12pt}\selectfont \textbf{Philippe Wenk}} </latex>
<latex>{\fontsize{10pt}\selectfont \textit{Semester Project, RSC}} </latex>
<latex> {\fontsize{12pt}\selectfont \textbf{Abstract} </latex>
In learning control, collecting data is often expensive. Thus, data-efficiency is a crucial requirement for any algorithm. PILCO is a model-based reinforcement learning algorithm based on probabilistic, non-parametric Gaussian Process models, able to perform with significantly less samples than traditional RL algorithms. 1)
In this semester thesis, a Gaussian Process framework and a theano-based implementation of PILCO were implemented in python. Two different approaches are presented with which it is possible to control a robotic planar arm with two joints.
<latex> {\fontsize{12pt}\selectfont \textbf{Problem setting} </latex>

In this project, a robotic arm with two joints should be controlled. As shown in the animation, the arm starts with its elbow joint angled at 90 degree and stops when the arm is fully stretched. The arm was assumed to lie on a frictionless plane with two actuators, one for each joint. Using the joint angles and the joint angle velocities, the system had 4 states. To computationally simplify the problem, only policies based on linear state feedback were considered.
<latex> {\fontsize{12pt}\selectfont \textbf{GP Framework} </latex>
For modeling the system dynamics, PILCO chooses Gaussian Processes. GPs are a regression technique that calculate the mean and the covariance of a gaussian prediction of a scalar target variable given a feature vector as input. Thus, four different GP models had to be trained, one for each state of the arm model.
GP models exploit the fact, that similar inputs lead to similar outputs. Similarity is measured using one kernel function that defines the whole model structure. There exist many different choices and complicated constructs. In this project, two simple ones were implemented and tested in the PILCO main loop, a 'linear' and an 'exponential' kernel.
Analysis of the prediction quality showed that the linear kernel is outperformed by the exponential one in almost all cases. Only for simple linear dynamics, the linear kernel was performing satisfyingly. However, it can be implemented very efficiently, as all significant calculations can be reduced to matrix multiplication.
<latex> {\fontsize{12pt}\selectfont \textbf{Controlling the Arm} </latex>
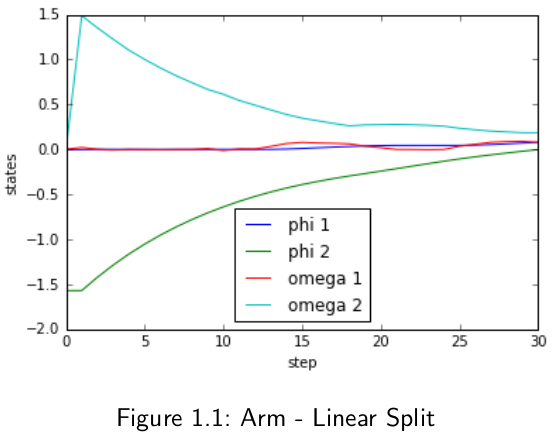
Two different approaches were explored to ultimately control the arm using PILCO. Using the exponential kernel, it was possible to fit the system dynamics with reasonable errors. However, the running time of the algorithm was enormous, a full convergence is estimated to take around 7-9 days. Thus, this experiment was stopped after the first optimization and the resulting trajectories were plotted in Figure 1.1.
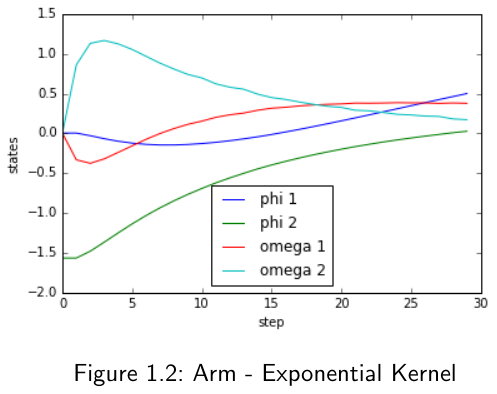
This running time issue could be mitigated by using sparse GPs 2) as suggested in the original paper. However, there exists a different approach. As the linear kernel is both computationally tractable and able to fit simple dynamics, the experiment was split into 6 equal sized time slices. For each slice, a different kernel was trained. Thus, the kernels only need to fit simpler, local dynamics. Due to the significant gain in computation time, this allowed for optimizing a more complicated policy. So for each time slice, there was also a different state feedback gain matrix used. The results are shown in Figure 1.2.
 |  |
<latex> {\fontsize{12pt}\selectfont \textbf{Conclusion} </latex>
Splitting the trajectories was obviously successful. Even though the exponential case was not allowed to finish, it shows promising steps in the right direction, as PILCO pushes the states to zero as desired.
To improve scalability of the algorithm, it would be a good idea to include a sparse GP implementation. For a wider applicability, nonlinear policies should be considered further in future work, e.g. by implementing a policy represented by a deterministic Gaussian Process as mentioned in the original paper. To further improve data efficiency, it might be a good idea to look either at more specific kernel structures, using regularization or priors to avoid over-fitting, or to use GP prediction models that are capable of capturing correlations between different target dimensions, e.g. by following Cressie3).
Page Tools
